

Cracking (also referred to as reverse engineering) is the process of finding software components and functionalities in order to modify / find vulnerabilities / disable features that are undesired by the "cracker".
This can be used for shady things like disabling copy protection features, but also for positive Things like removing bugs from an otherwise loved but old and not any more supported application, improving security, retrieving lost source code, and even researching/analyzing computer viruses/malware.
Today, we're going to take a look at how you can start reverse engineering software and how you can defend against others cracking your software.
This way (whatever side you're on 😉) you understand what the other side is doing and how to combat it.
1. How to crack Software
1.1 Decompiling
The first method of cracking Software is Decompiling. This simply means converting your compiled EXE/DLL/binaries/etc back to source code.
This works best with some languages such as Java and C#, because those languages are so-called Jiter languages, that have a different compilation procedure then Compiler languages or Interpreter Languages - they are first compiled to an Intermediate Code Language (C# → .exe OR Java → .class/jar), then compiled just in time (JIT) to the assembly of the target processor using an Interpreter. (You should check this article out, if you want to learn more about the differences between Compiler, Interpreter and Jiter Programming Languages )
That's why you need the .NET Framework or the Java Runtime System to run these programs - they're acting as the interpreter.
See the following graphic for illustration:
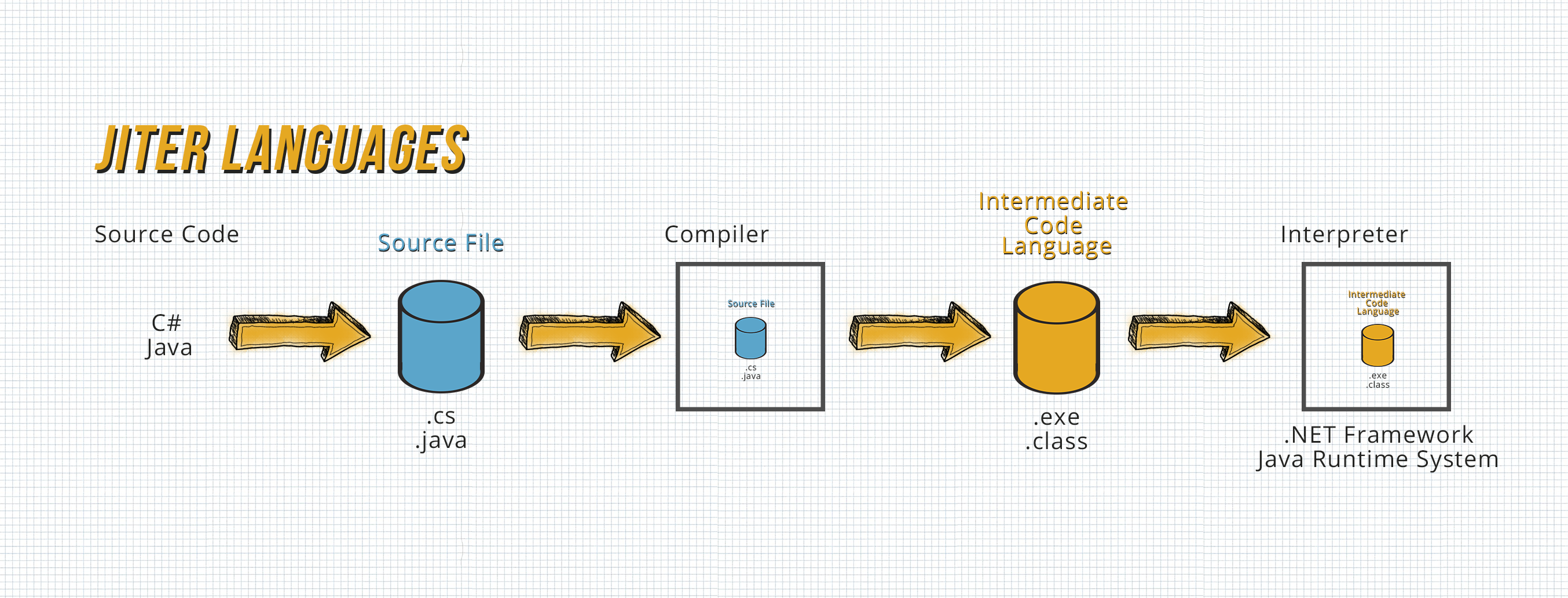
But that's also why you can decompile the program back to a close (not completely equivalent) copy of the original high-level code.
Now that you know why Decompilation is possible, lets look at how it can be done.
I'll show it to you using a C# example, but the process is pretty much the same for Java, you just need to use other Decompiler tools.
The first thing you will need to decompile a C# .exe is…. A Decompiler - who would have thought?
I personally suggest Telerik’s JustDecompile AND JetBrain’s dotPeek AND dnSpy.
Why would I recommend that you use three different decompilation programs? Well, that's pretty easy. It's got to do with Obfuscation. In point 2.2 I'm going to get further into what obfuscation is, but to put it simply: some obfuscation tools let dotPeek Crash, some let JustDecompile Crash and some let dnSpy crash.
But furthermore dotPeek and JustDecompile just let you look at the decompiled code (which could be enough if you just want to analyze the code) but if you also want to edit the code, you need dnSpy.
In my experience, I could decompile most of the .exe file I've found using at least one of these programs (there are still some obfuscation methods' that make all of them crash, but to get around that you have to crack your program using the method I talked about in Point 1.2 “De-Obfuscation” or 1.3 "Assembly Code" instead of Decompilation)
Okay, then let's get started now. I built a really simple little CrackMe (A CrackMe is a program created to test someone's reverse engineering skills.) program written in C# that checks whether you have a valid License Key.
Now our goal is to make the program always say that you have a valid license key even if you enter gibberish. You can try it yourself by downloading the CrackMe.exe here and opening it using DotPeek or JustDecompile or dnSpy, or you can just follow me.
Since I know that I will want to edit the code I will use dnSpy.
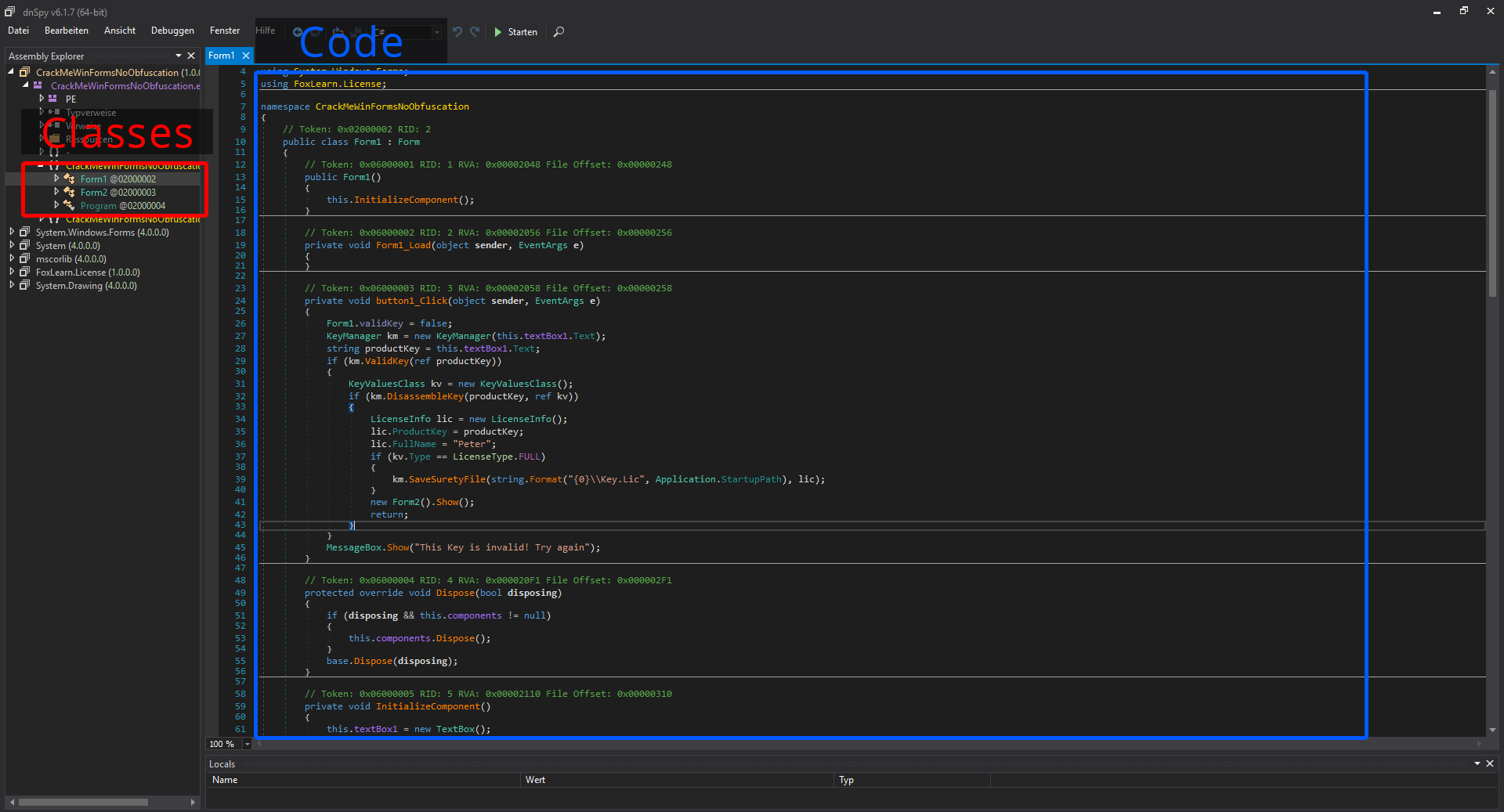
- Open the CrackMeWinFormsNoObfuscation.exe in dnSpy to find the three classes: “Form1”, “Form2” and “Program”.
- Click on the first class “Form1” to see the code open on the right side.
- After analyzing the code for a bit you will see that you have to modify the
.ValidKey()and.DisassembleKey()functions to always returntrue. - Edit the Code (See following Video).
You may be asking yourself why I got into the functions that check the key instead of just writingif(true). Well, that's to make sure that if the .ValidKey() function is called somewhere else, it still says that any Product Key is valid.
Now let's test it (See following Video)
It works like a charm! But because most programs won't be so easy to modify, let's look at 1.2 De-Obfuscation, which will get you a little further, and then at 1.3 Assembly Code, which will allow you to reverse engineer EVERY program.
1.2 De-Obfuscation
Obfuscation is the transformation of source code into a new representation that is more difficult to understand, copy, re-use and alter, but the obfuscated output has the same functionality of the original code.

Obfuscation makes it impossible to restore the obfuscated code back to the 100% original, but with certain De-Obfuscation software it can be reverted/re-build to a near copy that is at least human-readable.
Obfuscation is used in every Programming Language there is - No matter if it's a Compiler, Jiter or Interpreter Language. That is why there are also loads of different tools for Obfuscation and tailor made de-obfuscation tools as their counterparts.
You're not always lucky enough to find a good de-obfuscation tool for your obfuscated program that you're trying to reverse engineer. In that case, your only answer would be 1.3 Assembly Code (This one however, will work for sure no matter how obfuscated and weird your program is).
I will give a C# and a JavaScript example for de-obfuscation, but if your program is written in something else just google for a tool and try different ones.
C#
For C# there are loads of different of obfuscators, but one de-obfuscators that supports 15+ of them is de4dot which you can download here.
It has loads of different features like:
- Decrypt strings statically or dynamically
- Rename symbols. Even though most symbols can't be restored, it will rename them to human-readable strings. Sometimes, some original names can be restored, though.
- Decrypt other constants. Some obfuscators can also encrypt other constants, such as all integers, all doubles, etc.
- Remove proxy methods. Many obfuscators replace most/all call instructions with a call to a delegate. This delegate in turn calls the real method.
- Decrypt resources. Many obfuscators have an option to encrypt .NET resources.
- Remove tamper detection code
- Inline methods. Some obfuscators move small parts of a method to another static method and calls it.
- Remove anti-debug code
- Control flow de-obfuscation. Many obfuscators modify the IL code so it looks like spaghetti code making it very difficult to understand the code.
- Restore class fields. Some obfuscators can move fields from one class to some other obfuscator created class.
- Decrypt embedded files. Many obfuscators have an option to embed and possibly encrypt/compress other assemblies.
- Convert a PE EXE to a .NET EXE. Some obfuscators wrap a .NET assembly inside a Win32 PE so a .NET decompiler can't read the file.
- Removes most/all junk classes added by the obfuscator.
JavaScript
For JavaScript, I got some ideas from this StackOverflow question where someone encoded their own code and hadn’t done a backup of the original.
Here is what the obfuscated Code looks like:
var _0xf17f=["\x28","\x29","\x64\x69\x76","\x63\x72\x65\x61\x74\x65\x45\x6C\x65\x6D\x65\x6E\x74","\x69\x64","\x53\x74\x75\x64\x65\x6E\x74\x5F\x6E\x61\x6D\x65","\x73\x74\x75\x64\x65\x6E\x74\x5F\x64\x6F\x62","\x3C\x62\x3E\x49\x44\x3A\x3C\x2F\x62\x3E","\x3C\x61\x20\x68\x72\x65\x66\x3D\x22\x2F\x6C\x65\x61\x72\x6E\x69\x6E\x67\x79\x69\x69\x2F\x69\x6E\x64\x65\x78\x2E\x70\x68\x70\x3F\x72\x3D\x73\x74\x75\x64\x65\x6E\x74\x2F\x76\x69\x65\x77\x26\x61\x6D\x70\x3B\x20\x69\x64\x3D","\x22\x3E","\x3C\x2F\x61\x3E","\x3C\x62\x72\x2F\x3E","\x3C\x62\x3E\x53\x74\x75\x64\x65\x6E\x74\x20\x4E\x61\x6D\x65\x3A\x3C\x2F\x62\x3E","\x3C\x62\x3E\x53\x74\x75\x64\x65\x6E\x74\x20\x44\x4F\x42\x3A\x3C\x2F\x62\x3E","\x69\x6E\x6E\x65\x72\x48\x54\x4D\x4C","\x63\x6C\x61\x73\x73","\x76\x69\x65\x77","\x73\x65\x74\x41\x74\x74\x72\x69\x62\x75\x74\x65","\x70\x72\x65\x70\x65\x6E\x64","\x2E\x69\x74\x65\x6D\x73","\x66\x69\x6E\x64","\x23\x53\x74\x75\x64\x65\x6E\x74\x47\x72\x69\x64\x56\x69\x65\x77\x49\x64"];function call_func(_0x41dcx2){var _0x41dcx3=eval(_0xf17f[0]+_0x41dcx2+_0xf17f[1]);var _0x41dcx4=document[_0xf17f[3]](_0xf17f[2]);var _0x41dcx5=_0x41dcx3[_0xf17f[4]];var _0x41dcx6=_0x41dcx3[_0xf17f[5]];var _0x41dcx7=_0x41dcx3[_0xf17f[6]];var _0x41dcx8=_0xf17f[7];_0x41dcx8+=_0xf17f[8]+_0x41dcx5+_0xf17f[9]+_0x41dcx5+_0xf17f[10];_0x41dcx8+=_0xf17f[11];_0x41dcx8+=_0xf17f[12];_0x41dcx8+=_0x41dcx6;_0x41dcx8+=_0xf17f[11];_0x41dcx8+=_0xf17f[13];_0x41dcx8+=_0x41dcx7;_0x41dcx8+=_0xf17f[11];_0x41dcx4[_0xf17f[14]]=_0x41dcx8;_0x41dcx4[_0xf17f[17]](_0xf17f[15],_0xf17f[16]);$(_0xf17f[21])[_0xf17f[20]](_0xf17f[19])[_0xf17f[18]](_0x41dcx4);};
Because JavaScript is an interpreter language which is pretty open in its nature... - See following graphic:
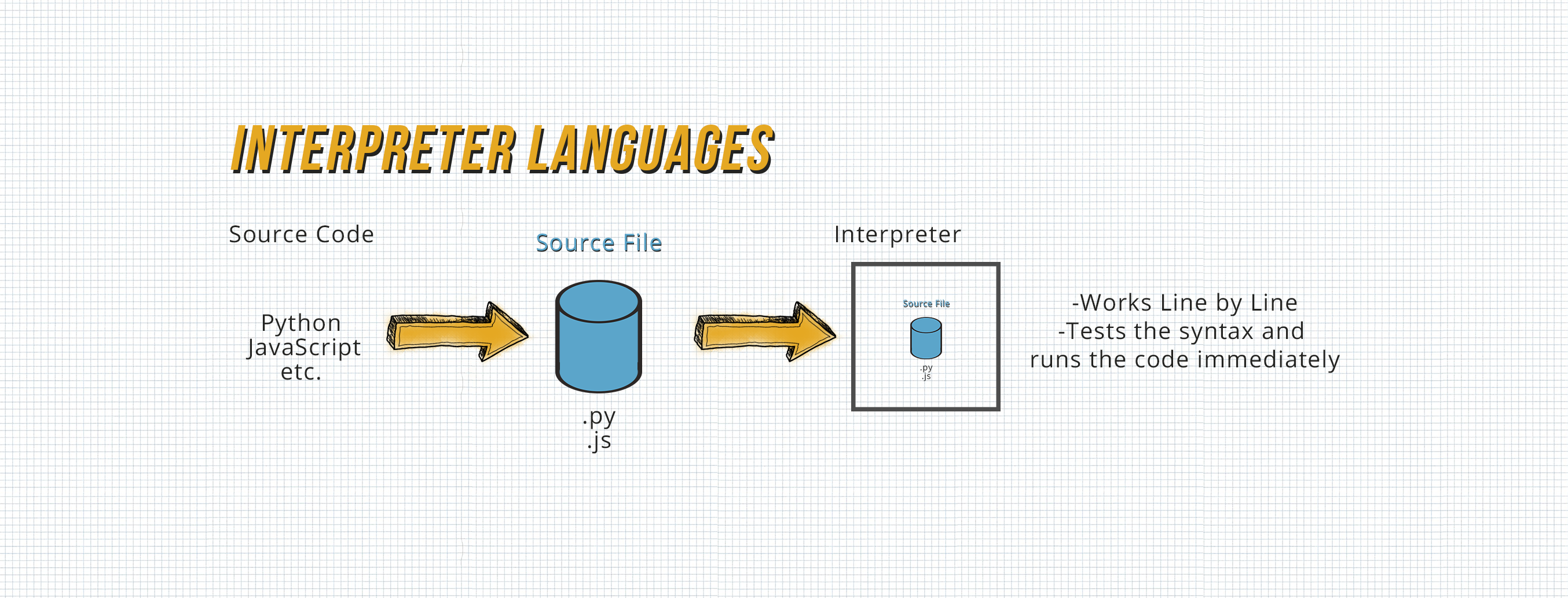
…most JavaScript beautifiers which aren't even specifically made for de-obfuscation will do the Job.
See jsBeutifier.org which for example works quite good with the obfuscated code of the StackOverflow question:
function call_func(_0x41dcx2) {
var _0x41dcx3 = eval('(' + _0x41dcx2 + ')');
var _0x41dcx4 = document['createElement']('div');
var _0x41dcx5 = _0x41dcx3['id'];
var _0x41dcx6 = _0x41dcx3['Student_name'];
var _0x41dcx7 = _0x41dcx3['student_dob'];
var _0x41dcx8 = '<b>ID:</b>';
_0x41dcx8 += '<a href="/learningyii/index.php?r=student/view& id=' + _0x41dcx5 + '">' + _0x41dcx5 + '</a>';
_0x41dcx8 += '<br/>';
_0x41dcx8 += '<b>Student Name:</b>';
_0x41dcx8 += _0x41dcx6;
_0x41dcx8 += '<br/>';
_0x41dcx8 += '<b>Student DOB:</b>';
_0x41dcx8 += _0x41dcx7;
_0x41dcx8 += '<br/>';
_0x41dcx4['innerHTML'] = _0x41dcx8;
_0x41dcx4['setAttribute']('class', 'view');
$('#StudentGridViewId')['find']('.items')['prepend'](_0x41dcx4);
};
But another (even better) tool is JSNice which not even de-obfuscates code, but also tries to guess the variables names (But it doesn’t work really great with the code of the StackOverflow question so take this one with a grain of salt):
'use strict';
/** @type {!Array} */
var _0xf17f = ["(", ")", "div", "createElement", "id", "Student_name", "student_dob", "<b>ID:</b>", '<a href="/learningyii/index.php?r=student/view& id=', '">', "</a>", "<br/>", "<b>Student Name:</b>", "<b>Student DOB:</b>", "innerHTML", "class", "view", "setAttribute", "prepend", ".items", "find", "#StudentGridViewId"];
/**
* @param {?} _0x41dcx2$jscomp$0
* @return {undefined}
*/
function call_func(_0x41dcx2$jscomp$0) {
/** @type {*} */
var _0x41dcx3$jscomp$0 = eval(_0xf17f[0] + _0x41dcx2$jscomp$0 + _0xf17f[1]);
var _0x41dcx4$jscomp$0 = document[_0xf17f[3]](_0xf17f[2]);
var _0x41dcx5$jscomp$0 = _0x41dcx3$jscomp$0[_0xf17f[4]];
var _0x41dcx6$jscomp$0 = _0x41dcx3$jscomp$0[_0xf17f[5]];
var _0x41dcx7$jscomp$0 = _0x41dcx3$jscomp$0[_0xf17f[6]];
var _0x41dcx8$jscomp$0 = _0xf17f[7];
_0x41dcx8$jscomp$0 = _0x41dcx8$jscomp$0 + (_0xf17f[8] + _0x41dcx5$jscomp$0 + _0xf17f[9] + _0x41dcx5$jscomp$0 + _0xf17f[10]);
_0x41dcx8$jscomp$0 = _0x41dcx8$jscomp$0 + _0xf17f[11];
_0x41dcx8$jscomp$0 = _0x41dcx8$jscomp$0 + _0xf17f[12];
_0x41dcx8$jscomp$0 = _0x41dcx8$jscomp$0 + _0x41dcx6$jscomp$0;
_0x41dcx8$jscomp$0 = _0x41dcx8$jscomp$0 + _0xf17f[11];
_0x41dcx8$jscomp$0 = _0x41dcx8$jscomp$0 + _0xf17f[13];
_0x41dcx8$jscomp$0 = _0x41dcx8$jscomp$0 + _0x41dcx7$jscomp$0;
_0x41dcx8$jscomp$0 = _0x41dcx8$jscomp$0 + _0xf17f[11];
_0x41dcx4$jscomp$0[_0xf17f[14]] = _0x41dcx8$jscomp$0;
_0x41dcx4$jscomp$0[_0xf17f[17]](_0xf17f[15], _0xf17f[16]);
$(_0xf17f[21])[_0xf17f[20]](_0xf17f[19])[_0xf17f[18]](_0x41dcx4$jscomp$0);
};
But watch out! Most JavaScript Obfuscation Tools, such as obfuscator.io, may even incorporate junk code that most Beautifiers can not delete and must be ignored by your programmer instinct.
1.3 Assembly Code
But what if you tried to decompile and de-obfuscate your program, but you still couldn't crack it?
Answer:

(Normally, I try to stay away from cheesy GIFs and I hope I didn’t cause any seizures, but this came to my head right away when I wrote this, and I like SpongeBob all right?)
Debugging the assembly code of an app is the answer to everything (Besides 42). By debugging the assembly you are able to reverse engineer EVERY program there is. No matter how well obfuscated it is or if it's an Interpreter, Jiter or Compiler language.
The last one is very closed in its nature and that’s why it mostly has to be cracked using this Method. See following graphic:
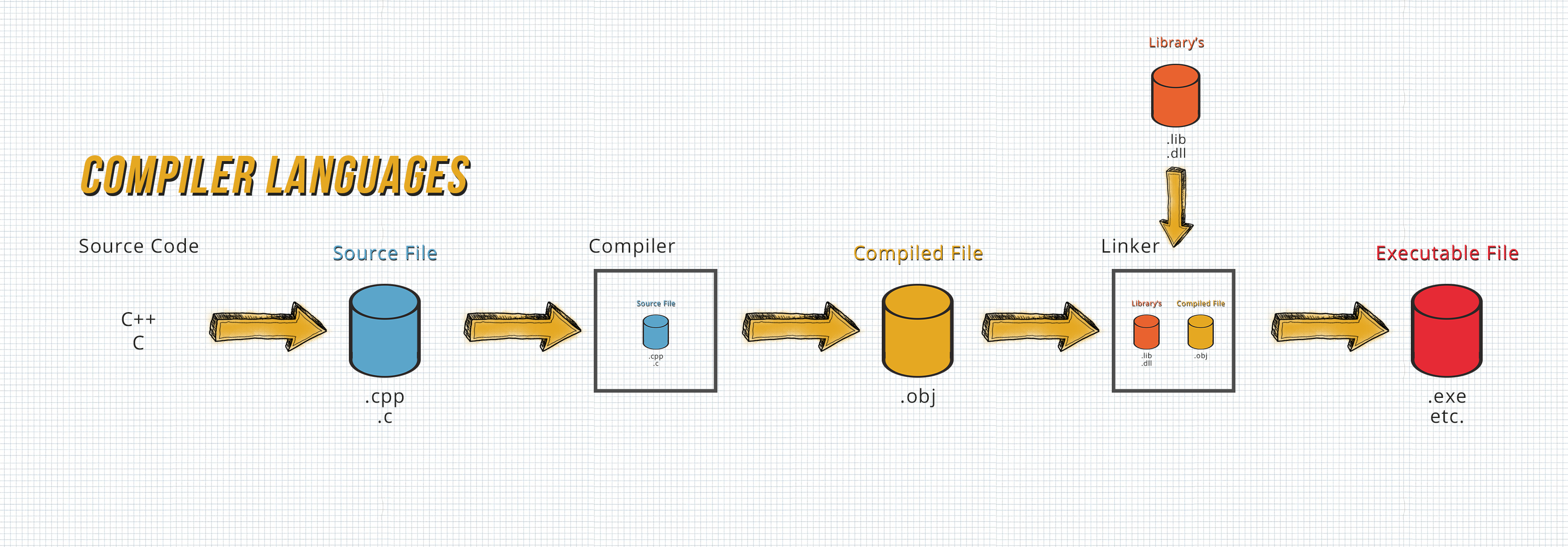
But what even is this “Debugging of the assembly code”?
Assembly language is a low level programming language for the processor. It is the simplest programming language available to any processor. With assembly language, the programmer only deals with operations that are performed directly on the physical CPU.
That means, in turn, that any High Level Program (regardless of how obfuscated it is) has to be converted into assembly language at some stage. And that means that instead of attempting to modify the high-level code (C#, C++, Java, whatever) you can alter the assembly code.
Obfuscation will still get into your way by making the Assembly Code harder and more complicated to read, but with enough experience, time, skill (and maybe luck) you will be able to crack any program.
First, let's compare some C++ code with x65-64 gcc 10.2 Assembly (There are tons of different assembly flavors, since each processor has its own, but they are all very similar.), second, how you can learn Assembly, and then let's see how you can crack a program and what tools you need.
Here you can see some C++ code on the left and the corresponding Assembly code on the right. If you never dealt with Assembly before it could be quite confusing at first but just go through the code line by line, maybe remove some things, add some things, and so on to get a better understanding.
You should look particularly at jle, jmp and jg. Those are so-called “Jumps” and “Conditional Jumps”. Those are the If statements you know - They JUMP to a particular line of code if some condition is met or just get ignored and go into the next line if the condition is not met.
Or in the case of the simple jmp it always jumps to a particular line without a condition having to be met.
You should check out this site (The best thing to do is open it in a new tab.) to learn more about jumps, because there are tons of different jumps that do all sorts of things.
Now with that out of the way, how can you learn more about assembly? LiveOverflow gave a great tip about this, in this video about reverse Engineering, I think.
Like I already did above (You can even use the Website I used here) you should write some C++ (Or whatever code) and then compare it to the assembly.
Even try to write a very confusing and complicated code to see how it would look like in the assembly, and if you think you'd be able to understand it if you hadn't seen the original High Level Code.
Now let's get into how you would crack a real program.
The first thing you need, is a Debugger. Personally, I always liked x64dbg (or x32dbg for x32 Programs), but a lot of people like OLLYDbg and IDA Freeware, too. But more "recently" (since 2019) Ghidra, a NSA tool, has been released. Yes, THE NSA. They even got a GitHub Profile.
You can get Ghidra from the NSA’s official page for Ghidra here or get the whole source code from their GitHub here.
Now let's look at an example where I try to crack this CrackMe using x32dbg - x32dbg instead of x64dbg because this is a 32-Bit Program! (The Password for the .ZIP is: “crackmes.one”). Try to do it on your own or just follow me.
If you open the .EXE in your debugger of choice it will look similar to this:
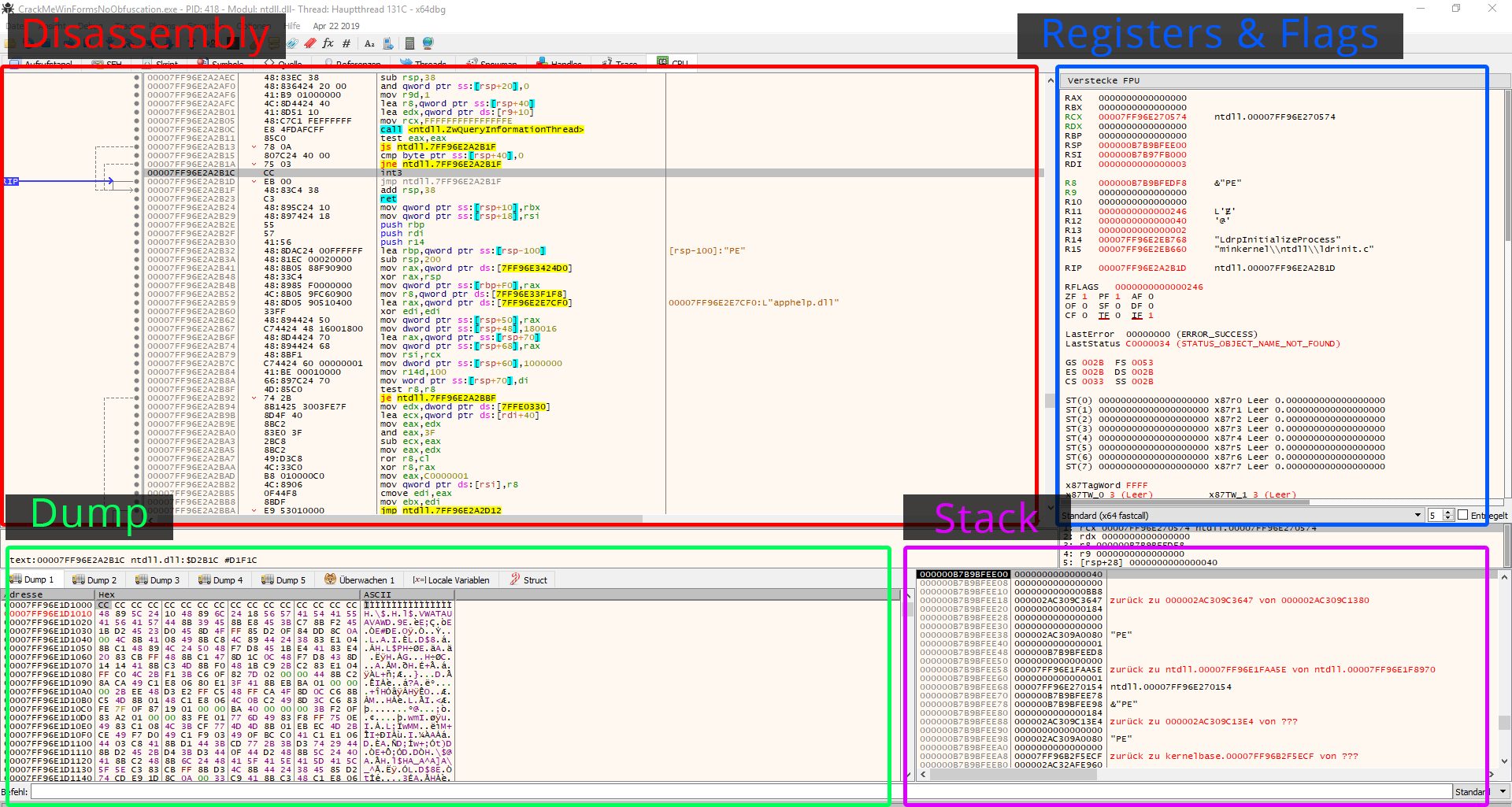
Disassembly
This is the assembly code I've already been talking about.
In the disassembly window of x64dbg, the first column displays the address of the instructions in the memory. The second column displays the opcodes or OPeration Codes. The third column shows the assembly code, which is the most important thing. In the 4th column, the debugger displays comments about instructions.
Dump
The Dump window displays the program's hex code in the memory. It's just like a hex editor that displays raw data in both hexadecimal and ASCII / UNICODE. If you want to change something, just double-click on what you want to change and adjust the bytes.
Registers & Flags
This section displays the registers used to perform mathematical operations. 32-Bit Intel processors typically have 8 general purpose registers, and 64-Bit Intel processors typically have 16.
Flags are showing you the current state of the processor. You can change individual flags by double-clicking them (at least in x64dbg).
Stack
The stack is memory space used to store data on a temporary basis. It stores data in either the LIFO(Last In First Out) or the FILO(First In Last Out) order. You can also check out this article if you are interested in learning more about stacks.
This is an example of the LIFO order:
Now your job is it to find the if statement - or rather the jump where it decides if your answer is valid.
This can be done by first analyzing the program. What happens when I enter some gibberish?
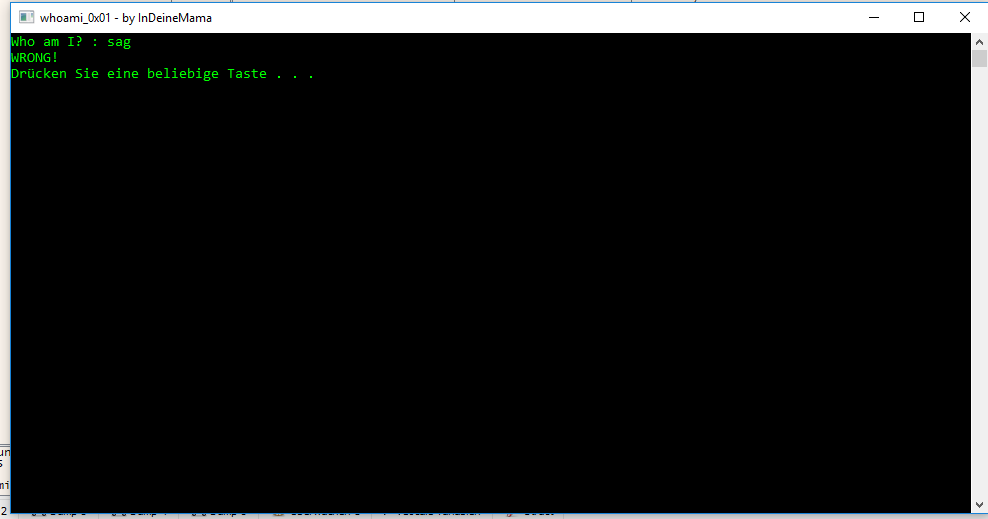
It just says “WRONG!”. Now there are two options:
The first one would be just putting break points at random points and then stepping through the code line by line to find the right jump (If statement). This has to be done for some programs.
But the second options would be a lot easier - searching for the string “WRONG!” and then looking what jump leads to it.
We're going to take the second option. Searching for a string can be done as follows in x64dbg/ x32dbg:
By the way, string scanning can often take longer on large programs.
As you can see there is a jump when equals (je) right above the part that outputs “WRONG!”. That means that if that condition behind the je is satisfied it will output “WRONG!”
In some programs it would be enough to change the je to a jne (JUMP when not equals), but in this program it just would do nothing if you would do that. Try it out if you want - Double-click on the je and change it to jne, click OK and then input something into the Program.
But luckily if you scroll up a bit you will See another “je” just above a line that would output “RIGHT!” 🤔 (No kidding, it could look like this in real programs, too).
So lets change that je to the opposite, which is jne. (By the way, I also know that the right Passphrase is written Out there, but I want to teach about jumps)
And if you now enter gibberish it will always tell you “RIGHT!” (besides when you enter the “Real answer” of course)
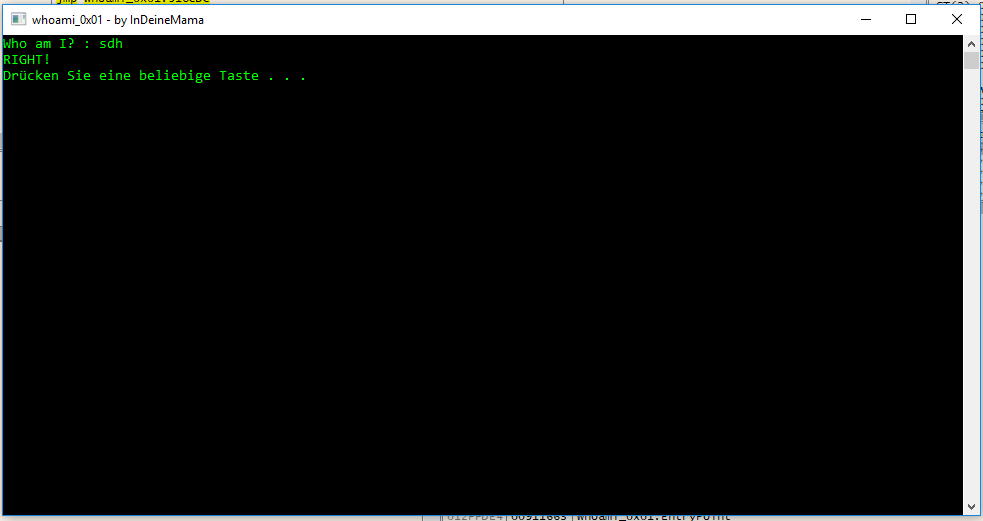
Now everything you have to do is to export (patch) the original .EXE.
Follow this Video:
Congratulations! You cracked your first program 🥳
If you want to learn more about debugging, or if you want to see what I just explained in video form with a voice, you should check out this video:
Or these videos where there is less explanation but more real world cracking:
If you are interested in more and harder CrackMe’s you should check out this site (Note that all Zips are Password Protected with “crackmes.one” or “crackmes.de”). Try to play with them and get harder and harder ones over time.
At some point, you could even try to reverse engineer a real program. Try to reverse engineer real malware or even some Kind of tool. But don’t break any licenses 😉.
2. How to protect your Program from cracking
2.1 Server Side Execution
This is probably the best way to protect your program from reverse engineering if you have the possibility to do this.

Instead of giving users access to your software, it's streamed from a server under your control, and they're never going to see the binary. The only thing you're giving them is the data they need to drive the UI.
This is the strategy that all MMOs use. People may re-engineer what you are sending to the UI and imitate the logic that is going on on your servers, but they will never be able to see what it is doing, and if your program is complicated enough, it might not be possible for the user to re-engineer the server side code. Simple as that.
Create a nice web GUI that forwards user inputs to a server which then just returns the results to the website.
But there are obvious pros and cons of doing this.
Pros
- Performance
This is also a con because the program can have an advantage in efficiency if it is running on a server, but it may also have a disadvantage if it is running on a server.
The benefit is that when your program needs to do some heavy computing that would normally take a long time on most user PCs, it can be broken up for server arrays with loads of CPUs & GPUs.
(Scroll down to see the performance disadvantage)
- Compatibility
The big pro of using a web interface instead of a native app is that a web app can be run on any device where a semi-modern browser is also available.
You're not going to have to worry about OS Wars between Windows, Linux and Mac. You're just going to have to worry about browser compatibility.
- Reverse Engineering Protection
The reason I'm even talking about the pros and cons of server side execution. As long as your servers are not breached, no one will ever be able to get your original source code.
But this doesn't mean that your software is going to be protected from manipulation. You still have to secure the endpoints of your API, because with enough will, someone will find a way to exploit them as they want.
Cons
- Performance
This was already the case in the Pros above, because heavy calculations can be run on gigantic server arrays. The downside, however, is mainly latency. A web interface will make 90% of programs feel slower than the native software.
- Server costs
Well, this is probably the biggest con. Instead of providing a website where people can download your software and it doesn't require much more power if you have more users, you will have to have powerful servers that will have to scale with your user count.
The technological aspect of scaling is not that big a deal in the era of AWS and cloud computing.
But the financial factor is a kind of issue, because instead of having a fixed cost per user for a website server, you will have a variable cost because you will have to upgrade your servers every n number of users.
- Server availability
This is another major con of server side execution.
Can you guarantee that your service will be up in 10 years, 20 years, or ∞ Years? Of course, you can't do that. That's also why a lot of people really hate “always online games” and SaaS apps.
So the only thing you could do is make your code publicly accessible before you stop working on your program for some reason (Bankruptcy will probably be the reason if you're a SaaS company)
2.2 Obfuscation
Code obfuscation is an intentional act of making source code difficult to modify and understand by renaming stuff, using hard-to-read functions (hard to read for humans, not for computers), blurring code flow, inserting dead code, ordering code randomly, and more.
There are obviously several Pros and cons to Code Obfuscation. See following:
Pros
- Reverse Engineering Protection
The reason I'm even talking about the pros and cons of obfuscation, as I said in Point 2.1, is that no one will ever be able to obtain 100% of your original source code. How much source code can be retrieved will differ depending on the obfuscation and de-obfuscation used, but the renamed variables and things like that, in particular, can never be recovered.
- Performance
This is similar to the performance aspect I talked about in 2.1. Obfuscation can make your code longer (if you want to hear about that, scroll down a bit), but it can also make your code smaller, speed up the process of compilation and let your app run faster.
This can happen because obfuscators do not care about human readability, which is why a lot of metadata, unused duplicate code of dead code, will be removed.
The Obfuscator does this with the goal of making it harder to read and not to optimize the code but it still works ¯\_(ツ)_/¯.
Cons
- Performance
As I said before, this could be a pro and a con. However, it's a con most of the time because the majority of obfuscators will make your code longer and run slower - By the way, you should not try to run your code through a Minifier after obfuscating it. This is going to break your code 90% of the time.
When you think of what the obfuscator is doing, this obviously makes sense. It adds weird stuff, dead code and encrypted values that a person will never use.
That's also why it's not always the best option to use the biggest and baddest of all obfuscators.
For instance, take the Movfuscator. It's a C++ compiler that doesn't use jumps or anything like that. It only uses move instructions. This results in code that looks like this:

Instead of this:

Yes most normal people would never try to reverse engineer that when they see it (Yes I'm calling everyone weird who would sit through reverse engineering that).
But as you can already see from the picture, it makes your code very very long and results in programs that take a couple of minutes to compile to taking hours.
- Anti Virus (False) Alarms
(I put brackets around the “False” because I don't know what you are going to do with the info I give you 😉.)
Antivirus systems learn from analyzing viruses - Most viruses don't want you to see how they work - that's why they get obfuscated.
But because of that, antivirus programs learn to ring the alarm bell every time they see obfuscated code.
This gets especially evident when you obfuscated code harder and harder. This also gives you the funny result that sometimes it’s better to obfuscate your virus less so it gets detected by less Anti Virus programs.
So find a good middle ground.
- Harder debugging
This is a very minor issue, but when a (paying) customer has an error and gives you a stack trace, it will be near impossible for you to track down the source of this stack trace and it would probably be better for you to ignore the stack trace and debug your software by asking the customer what he did (Which is how a lot of people still debug their app - That is why I’m calling this a minor issue).
2.2.1 Automatic Obfuscation Tools
There exists a range of tools that obfuscate codes, dependent on the language and the level of complexity of obfuscation. Since manual obfuscation takes time and has its limits, automatic obfuscation tools for all programming languages were born.
These tools apply the obfuscation methods I will take about in 2.2.2 and more that I will not talk about (like string encryption and stuff like that, because these are things you're not supposed to do manually, and let a computer do it).
So let’s look at a couple of them for some programming like C#, Python, HTML, JavaScript and C++.
I've also seen a lot of people obfuscating PHP - which I don't see the point in, because PHP will never be seen by the end-user because it gets executed server side. Perhaps they will send a paying customer obfuscated code for testing purposes and then send them the de-obfuscated code when they pay? Well, however, I'm not going to talk more about PHP obfuscation than this.
C# Obfuscators
As I've already mentioned, C# is a so-called Jiter Language, which makes it easier to decompile because it's not directly compiled to assembly, but to an Intermediate Code Language with a lot of metadata, which then gets JIT (Just in Time) run by an Interpreter (The .NET Framework in the case of C#).
See the following graphic for illustration if you forget about it or have not read the top part:
But nevertheless this can be obfuscated - Some obfuscators can even crash de-obfuscators.
Obfuscator's makes use of sophisticated obfuscation techniques to guard C# code from reverse engineering - Some features of automated obfuscator tools include a user-definable list of preserved names, a predefined list of reserved names, and stripping comments, symbol renaming to unintelligible names, Dead Code Injection, Debug Protection, hiding calls from external methods to hide critical methods, String Splitting, control flow Flattening, string encryption, etc.
My favorite C# Obfuscator is ConfuserEx. You can choose between different Presets (Minimum, Normal, Aggressive and Maximum). But you can also add or remove the different protection methods one by one.
It also includes a compressor so the end result doesn’t become too big - This is what i already talked about above in the Pros and Cons of automatic Obfusactors. With less aggressive obfuscation options this Obfuscator can even save you space.
It also joins all your dependencie .DLL’s together with the .EXE which will output you a single .EXE file instead of a whole folder of .DLL’s and a .EXE like you had before.
Python Obfuscators
Since Python is an interpreter Language it is very open in its nature.
See following graphic if you missed it above:
But there are still ways to obfuscate it. See PyArmor for example.
It is a command-line tool for obfuscating python scripts and binding obfuscated scripts to fixed machine scripts.
It obfuscates Python scripts by preserving constants and strings during runtime. PyArmor also verifies the license file of obfuscated scripts during execution and enables you to seamlessly substitute the initial python scripts with the obfuscated script.
Obfuscating HTML
HTML isn’t even a programming language because it’s missing the so-called “control structures” (sequence, selection, iteration).
But that doesn’t stop websites like twitter from obfuscating their HTML.
HTML is simply marked-up text which is beautified using HTML tags. Obfuscating HTML is typically done by converting it into JavaScript, renaming stuff like classes and ids, converting each HTML line into its corresponding numeric code.
While this works, it increases the size of your HTML by a lot, as a code overhead is added at each stage of transformation.
And it also increases the processing power required (in case you convert it to JavaScript), and there are people and browsers (for example, Tor) that don't even allow JavaScript to run.
That's also why it's best practice to make sure your website can be run with and without JavaScript.
So maybe you should stray away from certain HTML obfuscation tools.
But in case you don’t care: Snapbuilder.com has an HTML obfuscator that converts HTML to JavaScript. But in the end the Browser will still have to parse it all and which makes this pretty much useless.
Something you could do, is renaming classes and stuff like that dynamically on the server side using this PHP HTML Encoder for example.
This will at least make it harder for bots to scrape your site. But this can still be bypassed by just using XPath’s instead of class names. (By the way, check out this article if you are interested in how you can hide your Selenium Web Scraper from detection).
JavaScript Obfuscators
Like Python, JavaScript is an interpreter and "very open in its nature." Which makes it harder to effectively obfuscate it. I will still talk about two tools that try to do this.
Obfuscator.io
This is a fairly well-known tool that obfuscates JavaScript and converts your original JavaScript into a completely new representation, which is more difficult to understand and re-use.
It does various things with your code, such as debug protection by disabling console logging, variable and function renaming, self-defending features, and dead code injection.
It has a simple-to-use web interface where you can add your JavaScript and choose the necessary options based on your required degree of obfuscation - from rotating or shuffling string arrays, renaming global variables, encoding string arrays, converting all strings to their Unicode representation, etc.
It also contains control flow flattening, which hinders the understanding of source code. This feature, however, has a big impact on code efficiency by slowing down the runtime speed by around 50% (100% would be when in takes double the time, this means it takes 1.5x longer).
UglifyJS
UglifyJS makes output code harder to understand (compressed and ugly), but it can be easily transformed into something readable using a JS Beautifier - Yet maybe that’s what you are looking for, that's why I will still talk about it.
It has a great variety of options to minify, obfuscate, and beautify JS code. It consists of a parser that produces Abstract Syntax Trees, a compressor component that optimizes the Abstract Syntax Trees, and a mangler component to reduce names of variables and methods to single-letters.
C++ Obfuscators
The best way to obfuscate C++ code is to compile it and distribute only the binaries. This makes reverse-engineering the distributed code to its original form difficult. C++ machine code output after decompilation is itself “obfuscated”, hence it involves a level of obfuscation built-in (It’s just assembly code, which means that this is more Security through obscurity).
But as I mentioned above, there are still C++ Obfuscators like the Movfuscator, which is a C++ compiler that only uses move (mov) instructions. Yeah, you heard that right, no jumps or anything like that, just moves.
The result is code that would usually look like this compiled:

To look like this:

As I’ve already said, most normal people would never try to reverse engineer that when they see it (Yes I'm calling everyone weird who would sit through reverse engineering that).
But as you can already see from the picture, it makes your code very very long and results in programs that take a couple of minutes to compile to taking hours.
So use this tool sparingly.
If you want to be less aggressive there are still tools that obfuscate C++ the “normal way”. Take Stunnix for example. It mangles integers, strips spaces, strips newlines, hashes identifiers, removes comments and so on.
So use this or something similar if you don’t want the Reverse Engineerer to become crazy (I also talk about this “becoming crazy” thing in Point 2.4 Psychological Warfare).
2.2.2 Manual Reverse Engineering protection
In the following section I will discuss ways you can prevent reverse engineering manualy through different ways (Automatic ways of protecting against reverse engineering would be 2.2.1 Automatic Obfuscation Tools). Usually I'm going to give a code example in C++, but you should be able to take the idea and adapt it to any programming language you prefer.
Breakpoint Detection through Timing Attacks
Breakpoints are essential for the reverse engineer, and without them, a live analysis of the module does no good.
Breakpoints allow the program to be stopped at any point where it is put. Through doing this, reverse engineers can set breakpoints in areas such as Windows APIs, and can easily figure out where a bad boy message (e.g. a message box that says you entered a bad serial) is coming from.
In general, this is possibly the most commonly used cracking technique, the only competition will be a text string search (I talked about this in point 1.3 “Assembly code” above). This is why breakpoint checks are performed on important APIs such as VirtualAlloc, MessageBox, CreateDialog, and others that play an important role in the process of protecting user information.
And a cool way to detect breakpoints is timing - the concept behind timing is that running a section of code, especially a small section, should only take a certain amount of time. Therefore, if a timed portion of the code takes a longer time than a certain fixed limit, it is most likely that a debugger is attached, and someone is going through the code.
I'm not going to provide a Code example here, because I think you should be able to get the idea. You just need to check the current time at the beginning of a code block, and then later check the current time at the end of the code block - Calculate the difference between the two timestamps, to see if the code took longer than it should. (Do not use a timer. Those can be paused - Use timestamps and calculate the difference manually!)
Of course, you have to take into account that certain tasks can take longer on slower machines.
Removing the Portable Executable Header
This is a simple anti-dumping technique that removes an executable's portable executable from memory at runtime - by doing this, a dumped image would be missing important information such as the Relative Virtual Address of important tables (Import, Export, Reloc, etc), the entry point, and other information that the Windows loader needs to utilize when loading an image.
But you should be careful when utilizing this technique, because the Windows API or other legitimate external programs may need access to this information which has been removed.
Here is a Code example:
// Erase the current images PE header from memory preventing a successful image if dumped
inline void ErasePEHeaders()
{
DWORD OldProtect = 0;
// Get base address of module
char *baseAddr = (char*)GetModuleHandle(NULL);
// Change memory protection
VirtualProtect(baseAddr, 4096, // Assume x86 page size
PAGE_READWRITE, &OldProtect);
// Erase the header
ZeroMemory(baseAddr, 4096);
}
Virtual Machine Detection
This one is more useful if you were writing malware, since malware is usually reverse engineered in a Virtual Machine.
If you were writing normal software for people to use, you wouldn't care if it was installed in a VM or not, so you can overlook this section.
But if you've coded a virus, you don't want it to run in a VM because it wouldn't get you anything, because VMs are typically only online for a limited period of time, and the odds are high that your code would only be run in a VM because someone is trying to reverse engineer it.
There are plenty of different ways to find out if the device is a Virtual Machine. Here's a short list of things you should look for:
- Virtualized environment artifacts: registry keys, hard disk name, network card address, specific drivers, etc.
- Environment differences: no mouse, internet connection, sound card, etc.
- Lack of user interaction (specific for automated environment): no mouse movement, no file operations, etc.
- Specific environment differences: VirtualPC exception bug, VmWare backdoor, etc.
Since there are so many ways to find out if you're in a VM, I'm not going to write all the different ways out.
Just check out these paste bins if you want to see some code:
VirtualPc
- http://pastebin.com/wuqcUaiE (x0Fx3F TRICK)
- http://pastebin.com/HVActZMC (CPU ID Trick)
- http://pastebin.com/VDDRcmdL (0x0F 0x3F Combinations)
- http://pastebin.com/exAK5XQx (Reset Trick)
VirtualBox
- http://pastebin.com/xhFABpPL (Machine provider name)
- http://pastebin.com/Geggzp4G (Bios Brand and Bios Version)
- http://pastebin.com/RU6A2UuB (9 different methods, registry, dropped VBOX dlls, pipe names etc)
- http://pastebin.com/fPY4MiYq (Bios Brand and Bios Version)
- http://pastebin.com/AjHWApes (Cadmus Mac Address Trick)
- http://pastebin.com/v8LnMiZs (Innotek trick)
- http://pastebin.com/wh4NAP26 (VBoxSharedFolderFS Trick)
- http://pastebin.com/Nsv5B1yk (Resume Flag Trick)
- http://pastebin.com/T0s5gVGW (Parsing SMBiosData searching for newly-introduced or bizarre type)
Hypervisor
Debugger detection
Among the most popular debugging tools are: x64dbg (or x32dbg for x32 Programs), OllyDbg and IDA Freeware. More "recently" (since 2019) Ghidra, a NSA tool, has also become popular.
Since these are so popular and commonly used, detection methods have been developed to stop your code from running when a debugger is used.
Here, for example, is code for detecting the Olly Debugger
int __cdecl Hhandler(EXCEPTION_RECORD* pRec,void*,unsigned char* pContext,void*)
{
if (pRec->ExceptionCode==EXCEPTION_BREAKPOINT)
{
(*(unsigned long*)(pContext+0xB8))++;
MessageBox(0,"Expected","Debugger Detection",0);
ExitProcess(0);
}
return ExceptionContinueSearch;
}
void main()
{
__asm
{
push offset Hhandler
push dword ptr fs:[0]
mov dword ptr fs:[0],esp
}
RaiseException(EXCEPTION_BREAKPOINT,0,1,0);
__asm
{
pop dword ptr fs:[0]
pop eax
}
MessageBox(0,"Olly Detected","Debugger Detection",0);
}
IsDebuggerPresent
Another, perhaps the simplest anti-debugging method is calling the IsDebuggerPresent function. This function detects if the calling process is being debugged by a user-mode debugger. The code below shows an example of elementary protection:
int main()
{
if (IsDebuggerPresent())
{
std::cout << "Debugging Detected!" << std::endl;
exit(-1);
}
return 0;
}
The IsDebuggerPresent() function reads the value of the BeingDebugged field. If the process is being debugged, the value is 1 if not, it's 0.
There is also a similar CheckRemoteDebuggerPresent() function to determine if a remote process is being debugged, which can be used the same way.
This can be easily fooled, so this is just a small step to check for debugging.
Niche languages
This last one is more Security through obscurity so not perfect.
Software tends to be written in the most common language, such as C, C++, C#, and so on.
This is the consequence of two things:
First, the ease with which such software can be run on several versions of Windows (without the need to install additional system components)
Second, the high availability of tutorials, discussion groups, and samples of source code for these languages, making it reasonably easy for newbie developers to build malicious programs.
But since these languages are so common, the majority of tools for reverse engineering also exist for these languages.
Anti-Virus programs deal with common languages on a regular basis, so they are equipped with all the necessary resources and have no trouble breaking those programs into their basic elements.
On the other hand, programs written in niche programming languages, such as functional languages or business-oriented languages, are more difficult for analysts. Here are a few crackers:
Such programs also mostly have a very complicated structure; in many cases, their entire code is in the form of an intermediate language (or bytecode) or needs many megabytes of additional libraries that are difficult to analyze, not to mention time consuming.
Even when using a debugger, the assembly code will still look "wrong" compared to the C++ assembly that most crackers are used to.
There are a few dedicated resources for decompiling programs written in some of these languages, e.g. VisualFox Pro applications can be decompiled using ReFox, but these tools are relatively uncommon in this field because there is simply not much demand.
The famous Stuxnet Worm was developed partly using an obscure object-oriented framework for the C language, and researchers had a hard time figuring out what language the worm was written in.
There are of course way more ways to protect against reverse engineering, but this article is already 7000+ Words long. You could check out this article if you want to see more ways.
2.3 Legal / EULA / License
If you're worried about people cracking your application, the bottom line is that nothing but a restrictive license can give you protection. As you saw every program users have access to, can be reverse engineered using debugging.
And even systems that users do not have access to (Always Online Software) can at least be abused and, in the worst case, copied.
So the only thing you can really do against reverse engineering is a license filled with threatening statements like "This is software from ABC Company. Your access to it doesn't grant you permission to copy or distribute it" or something that threatens huge penalties if anyone leaks the software.
I'm not a lawyer, of course, but you can see a lawyer if you want to make sure the language of your license is going to hold up in court.
Then riddle your program with fingerprints that are unique to the person who buys the software so that when the program leaks, you can search your fingerprint database with payment details to see who did it - you must, of course, still obey the GDPR Privacy Regulations while doing so. This is the method the Hex-Rays use for their disassembler IDA PRO.
This approach is not going to stop piracy entirely, but it should deter a lot of crackers. And if it gets cracked at any point, it should allow you to recover some of the lost revenue associated with the software being leaked in the first place.
(By the way you also can’t just see cracked software as a revenue loss. Do you really think everyone who cracked the program would buy it if they couldn't get it for free? Of course, I never cracked software for my own 🤨, but if I put myself in the role of someone who did crack software, I would know that they just wouldn't get it if it wasn't free and would just be looking for a free alternative.)
One thing, however, is that you're going to have to put a lot of fingerprints in your code, and they're going to have to be subtle. If the attacker can get two copies of the program and compare the files between the two, the attacker would be able to tell what the identifying information is and then replace it with whatever they want.
The best way to do this is to add a lot of false hints into it that can't just be taken off or randomized, and make the ID code non-critical to running the software - if a cracker doesn't look at the ID stuff in the first place, he's more likely to just leave it in.
2.4 Psychological Warfare
Okay, this one is kind of a joke point but still a somewhat valid one.
As Chris says himself in the talk this is not really that useful, but the idea itself isn’t that bad.
Since you learned that you can crack/reverse engineer EVERY Program there is and everything stopping someone from doing it is the resources they have/want to put into cracking your program, instead of making it hard for them through obfuscation or scaring them through Legal action a good way to deter crackers is *CRUSHING THEIR SOUL*.
Make them not want to crack you program anymore, make them hate the idea of cracking it, get on their nerves, leave them *messages*.
I got this inspiration from the following DEF CON talk “Repsych: Psychological Warfare in Reverse Engineering” where Chris Domas talks about exactly this subject:
He first talks about the Movfuscator I already mentioned above, which compiles C++ code to ONLY Move instructions (If you skipped that part and just straight up scrolled down here, definitely check out 2.2 Obfuscation to see more about it) which kind of is Psychological Warfare already because no normal human being would try to reverse engineer that.
But later the talks about the Control Flow Charts in the IDA Debugger that normally look like this:
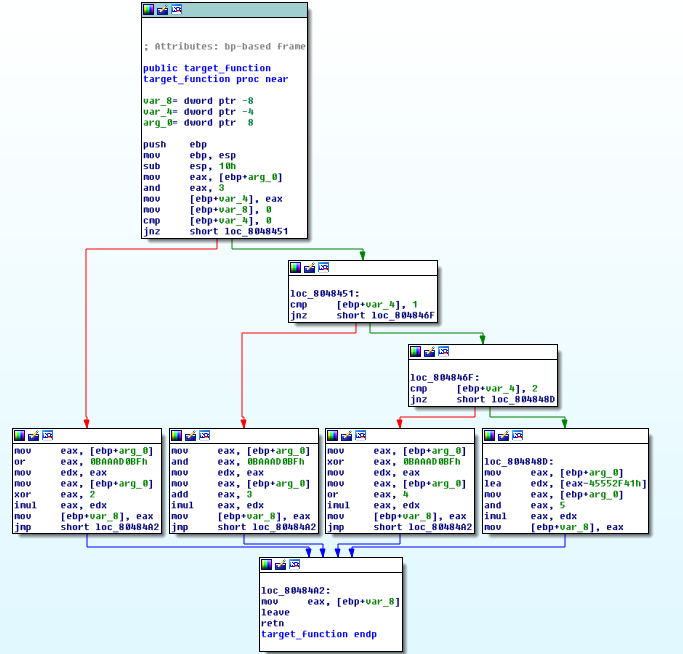
Picture Source: Deobfuscation: recovering an OLLVM-protected program
But Chris found out a way to “paint” pictures in them. He created a program that can convert pictures (even grayscale ones!) to control flow graphs.
This way he can hide cute puppies in the graphs:
(I couldn’t get a full screenshot of it but with a little imagination you can see the puppie on a beach - That’s another SpongeBob reference by the way.)
Or mean messages:
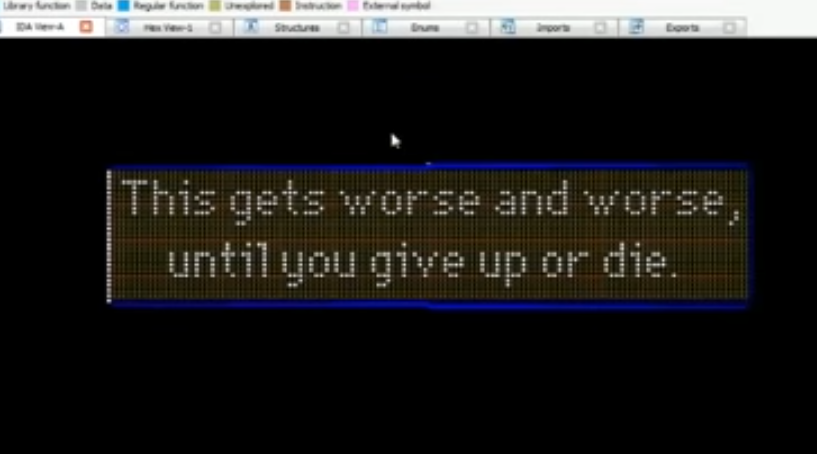
3. Further resources and Books
Besides some books that you can see below, DEF CON and Black Hat are fantastic resources to learn about things like this. Just search “DEF CON Talk” or “Black Hat Talk” on YouTube and you'll find loads of recorded talks.
I personally also like Give Academy and LearnThenTeach. Most of their videos are a bit older but not a lot has changed in reverse engineering with debugging tools in the last 10 Years, so check out their YouTube channels.

Reversing: Secrets of Reverse Engineering


Practical Malware Analysis: The Hands-On Guide to Dissecting Malicious Software
