

Before I begin, I've recently been receiving an increasing number of questions and messages about this article on a variety of different platforms due to a lack of clarity about how to contact me with questions about this article. So, if you have any questions, please send an email to contact@piprogramming.org and I'll get back to you as soon as possible :)
A lot of sites will block your web scraping / automation using Captchas, FingerprintJS, Imperva or their own similar tools because it puts an unwanted load on the servers of the site and raises the cost of maintaining the site without giving back any value. A business wants to use its resources to serve customers and not people who just want their data.
That's why they're tracking irregular browsing activities to block your web scraping efforts. But you're not giving up so easily right?😉 That's why I've put together a list of 10 things you can do to hide your automation using Selenium and make it undetectable as well as look like a real person.
1. Removing Navigator.Webdriver Flag
The Navigator.Webdriver Flag indicates whether the browser is controlled by automation tools such as Selenium and is also the Source of that "Chrome is being controlled by automated test software" notification bar you get when using Selenium with Chrome.
It is meant to be used as a standard way for websites to realize that automation tools are used. The website can then run alternate code to the code that would run for a regular user - like blocking scripts for example.
The Flag is set to true while Selenium Controls the Browser. But, by using basic analytical tools, every website will see that and figure out that you are using an automated browser.
It is usually set to true when the --enable-automation, the --headless flag, or the --remote-debugging-port is enabled in Chrome.
For Firefox the marionette.enabled Flag or --marionette has to be set.
The Analytics Tool on the Website would usually look something like this:
var isAutomated = navigator.webdriver;
if(isAutomated){
blockAccess();
}
But since it is so simple to check for the boolean it is also very easy to remove it on runtime by using the following Python Code which works for the Chrome WebDriver and the Firefox/Gecko WebDriver:
#Open Browser
option = webdriver.ChromeOptions()
browser = webdriver.Chrome(executable_path='chromedriver.exe',options=option)
#Remove navigator.webdriver Flag using JavaScript
browser.execute_script("Object.defineProperty(navigator, 'webdriver', {get: () => undefined})")
Or what is even better but only works when Using Google Chrome. Removing the Flag before it is even set. This way not even Chrome will know that you are using Selenium:
option = webdriver.ChromeOptions()
#Removes navigator.webdriver flag
# For older ChromeDriver under version 79.0.3945.16
option.add_experimental_option("excludeSwitches", ["enable-automation"])
option.add_experimental_option('useAutomationExtension', False)
#For ChromeDriver version 79.0.3945.16 or over
option.add_argument('--disable-blink-features=AutomationControlled')
#Open Browser
browser = webdriver.Chrome(executable_path='chromedriver.exe',options=option)
2. Obfuscating JavaScript of Browser Driver EXE
Even though I said EXE this also applies to you if you are using Linux or Mac 🙃.
At the time of writing, this point only applies to you if you're using a ChromeDriver.
If you open your ChromeDriver using a Text editor and go to approximately line 4000+ you will find some JavaScript that will be run when you are using Selenium.
That is why Bot detection software like FingerprintJS, Imperva (former Distil Networks), or Google’s Captcha will look for this JavaScript Code.
But luckily you can just edit this JavaScript right in the executable - just change up variable names with ones of the SAME LENGTH (otherwise Selenium will just crash).
If you are using the ChromeDriver the most Important variable is probably $cdc_asdjflasutopfhvcZLmcfl_. So replace the entire section just after $ with another string of the very same length. This is the variable most detectors are searching for. That being done, a lot of gates are already wide open to you.
In more specific terms:
- Open the chromedriver.exe using a Text editor. I would recommend Notepad++ with which you can just right-click the .exe and Choose: Edit with Notepad++
- Using Ctrl+F search for
$cdc_asdjflasutopfhvcZLmcfl_. It's on line 24816 in my current Chrome driver, but it's probably on a different line in yours. - Replace everything after the
$with something random of the very same length. E.g.$btlhsaxJbTXmBATUDvTRhvcZLm_(Just Hammer on your keyboard a bit and make sure that the new string is of the same Length) - Save this by pressing Ctrl+S. From now on, use this executable as your driver.
3. Changing Resolution, User-Agent, and other Details
One of the ways a Website will detect you is by creating a Browser fingerprint using your Monitor Resolution, User-Agent, and other details and then checking if you are making an abnormal amount of requests a Real Human could never make or applying other heuristics to detect if you are a Bot.
So by using Following Python Code, you can easily change them:
#Change Browser Options
option = webdriver.ChromeOptions()
option.add_argument("window-size=1280,800")
option.add_argument("user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36")
#Open Browser
browser = webdriver.Chrome(executable_path='chromedriver.exe',options=option)
Your goal should be to be as average as possible - because the more unique you are, the more trackable you are. For Example: Using a High-resolution screen but using an outdated User-Agent makes you rather unique.
You can check out AmIUnique.org where you can find out if your Browser Fingerprint is unique.
Why try to be average? Let’s say for example you make 1000 requests in 1 minute with your unique Resolution/User-Agent Setup. This will get flagged pretty fast because ONE Human could never visit that many pages in that time frame.
But if your Resolution/User-Agent Setup is being used by 1000 People who each make 1 request in 1 minute, your extra 1000 Requests would mean that each User on Average makes 2 Requests/minute. That is realistic for a Human.
But when changing your Monitor Resolution, User-Agent, and other details you shouldn’t forget about Consistency. If you are using the ChromeDriver you should use a Chrome User-agent because sites can find out about the real Browser you are using by executing JavaScript challenges like this one
eval.toString().length
The following Browsers will return the following values:
- Firefox: 37
- Safari: 37
- Chrome: 33
- Internet Explorer: 39
So, if the browser pretends to be Firefox in its User-Agent but the test returns 33, you will be probably get flagged as a Bot.
The same idea applies to OS consistency. Using following Code, a website can find out what OS you are really using:
navigator.platform
And these are the values returned for each OS:
- Windows: Win32 or Win64
- Android: Linux armv71 or Linux i686
- iOS: iPhone or iPad
- FreeBSD: FreeBSD amd64 or FreeBSD i386
- MacOS: MacIntel
- Linux: Linux i686 or Linux x86_64
4. Realistic Page Flow and avoiding Traps
Example: A real user has to visit the Home page first before clicking on Login because normally they do not know the URL for the Login Page off the top of their head.
That is why some sites set cookies when you visit a certain page and then when you make further requests, they will check if the cookies are present. They could also track page flow and look for patterns to determine whether the requests are from a real person
So to avoid getting detected make your Bot follow the steps you would have to follow. It will slow your Bot down but that’s better than getting blocked 😶.
In addition, traps such as non-visible links may also exist. For example, if you visit pages that are not allowed in the site robots.txt, the site may flag you as a Bot because those are often pages that are never linked to, so you will have to visit it directly by using the URL.
5. Changing your IP Address using Proxy’s
The Best way to scrape thousands of pages would be to distribute it on multiple machines with different Details.
But since different machines are way too expensive, why not change all identifying Details as I talked about in Point 3 “Changing Resolution, User-Agent, and other Details” and your IP Address.
Example: Like I already said. 1000 Requests is way too much for one person.
But 1000 Requests split between 100 “people” (Made up identities with different IP’s and Fingerprints) would only be 10 Requests per user.
To change your IP Address in Selenium using a Proxy you can use the following Python Code:
#Add Proxy
option = webdriver.ChromeOptions()
option.add_argument('proxy-server=106.122.8.54:3128')
#Open Browser
browser = webdriver.Chrome(executable_path='chromedriver.exe',options=option)
There are loads of Free Proxy’s on the Internet, but they are probably also used by loads of other Bots that have already been flagged - so now the IP is also flagged.
This is known as an IP reputation. The IP reputation factors in IP history, Number of visits from a IP, or if its a known public Proxy / Tor Proxy.
That is why a private Proxy you made yourself or bought private proxy could come in handy - but it’s definitely not a requirement for all scraping Projects.
Private proxies are essential if you are targeting a site with very specific IP requirements (for example, many Australian grocery websites only allow Australian IPs), or if you want to scrape a large amount of data - especially in short timeframes.
Residential oxylabs Proxies attached to physical locations appear more real and legitimate, helping you minimize the number of IP bans and CAPTCHAs - but in certain cases where you just need a lot of high speed IPs regardless of quality in terms of bot detection (some bot detection just check the IP address usage amount itself and ignore further reputation marks), Rotating ISP Proxies, which are also offered by oxylabs, could actually be better.
6. Using Random Delays
This is kind of a part of Realistic Page Flow - but I've made it a separate point because it's also about not requesting too much data.
First, let’s look at it from a Page Flow perspective - Humans and Bots don’t behave the same. You can imagine that a Bot tends to be faster than a human. No real user will read a News Article in 5 seconds. That is why websites track how many minutes you spend on the site, how many pages you visited, and so on.
So just add some delays between visiting Pages. But also don’t make it wait the same amount of time on every Page because that could also be noticed. Just let your Bot wait a RANDOM amount of time on a Site.
With that out of the way, let’s look at it from a “requesting too much data” perspective - Like I already said in my third point. No real user will ever request 1000 Sites in 1 Minute.
So just simply rate limit your Bot by only allowing it a realistic but fast enough (So you don’t have to wait until the Sun explodes😉) amount of requests it can make.
7. Do not use a Headless Browser
Who uses a Headless Browser? Definitely no Human. That is why Sites started to test if a Browser is Headless or not.
Depending on whether the browser is running in headless mode or not different features may be or may be not available. That’s what makes it possible to detect if a browser is running in headless mode or not.
Most tests are for Chrome because most Bots use Chrome nowadays. These tests aim to determine whether features are behaving as they should behave in regular Chrome, or whether they are behaving as in Headless Chrome.
One example can be seen here by checking the behavior of the permission’s API:
navigator.permissions.query({name:'notifications'}).then(function(permissionStatus) {
if(Notification.permission === 'denied' && permissionStatus.state === 'prompt') {
console.log("Headless Chrome");
} else {
console.log("Not Headless Chrome");
}
});
In Headless Chrome, the test returns values that do not make sense. On the one side, it says that permission to send notifications is denied when using Notification.permission. On the other side, it returns prompt when using navigator.permissions.query.
There are loads of these Tests available, I created a GitHub repository and an Article about further ways you can detect a headless browser here.
8. Captchas
Captcha’s (or Completely Automated Public Turing tests to tell Computers and Humans Apart) are one of the more difficult to crack anti-scraping measures, fortunately captchas are also incredibly annoying to real users.
This means that a lot of sites don't even use them, and when used they are normally limited to some forms.
But what if they do get in your way?
The first step to bypass captchas is to follow all the other steps listed here and to just click the button - but if that fails and your "humanity score" is too low, you are now faced with the problem of solving these all too familiar picture puzzles
Provided that Google reCAPTCHA V2, the original Captcha or a similar variant that is not made by google is used. With Google reCAPTCHA V3, these picture puzzles no longer exist and only a score between 0.1 to 0.9 is calculated based on the interactions the user makes. To bypass reCAPTCHA V3 your “only“ solution is to pay attention to the other points listed here or use a captcha Farm that supports reCAPTCHA V3 - You can check your reCAPTCHA Score here.
Breaking captchas can either be done via Artificial Intelligence (Computer vision / Speech to Text) tools or farms where real humans get paid to solve captchas for you. These services are available for even the latest Google image reCAPTCHA’s and simply impose an additional cost.
Captcha Farms
CAPTCHA farms will basically take the CAPTCHA test that you face, send it to a real human who will then complete it and then send the human-generated correct answer back to you with which you can now verify your "humanity."
There are many services out there that solve captchas for you and in turn, charge a small fee - normally you get charged per 1000 Captchas. A normal rate currently is $0.5 to $3 depending on the captcha Type. A few common services are 2captcha, anti-captcha.com and deathbycaptcha.
In the following example, I will use 2captcha to solve Google reCAPTCHA V2, but here you will also find a tutorial to solve reCAPTCHA V3 and here a tutorial for the normal old school captchas (By the way, I'm not associated with 2captcha at all, they just have tutorials for tons of different captcha styles).
1. Get Site Key from captcha
The site key is the exclusive key that every site gets when they implement reCAPTCHA V2. You will use this site key to send it to 2captcha. When you search the captcha element itself, you'll find the site key, like this:

Get this Key from the element using beautifulsoup4 or similar HTML Parser.
2. Send Site Key to 2Captcha
Now you need to send the site key you got from Step 1, Your 2Captcha API Key you get when you register and the URL of the site where the captcha is placed on to 2Captchas API.
See this Python Code example:
import requests
import time
from selenium import webdriver
siteKey = "6Le-wvkSAAAAAPBMRTvw0Q4Muexq9bi0DJwx_mJ-"
apiKey = "Place Your 2Captcha Site key here"
pageUrl = "https://google.com/recaptcha/api2/demo"
form = {"method": "userrecaptcha",
"googlekey": site_key,
"key": apiKey,
"pageurl": pageUrl,
"json": 1}
response = requests.post('http://2captcha.com/in.php', data=form)
requestId = response.json()['request']
3. Get request ID back and submit Form
url = f"http://2captcha.com/res.php?key={api_key}&action=get&id={request_id}&json=1"
status = 0
while not status:
res = requests.get(url)
if res.json()['status']==0:
# Response is not ready
time.sleep(3)
else:
# Response is ready
requ = res.json()['request']
# Open the Website with form using Selenium
driver = webdriver.Chrome(executable_path=r'.\chromedriver.exe')
driver.get(pageurl)
# Place the the request id received into the HTML of the Captcha
js = f'document.getElementById("g-recaptcha-response").innerHTML="{requ}";'
driver.execute_script(js)
# Click submit button
driver.find_element_by_id("recaptcha-demo-submit").submit()
status = 1
Captcha AI
You could write your own AI to recognize Images / AI to recognize Speech, use other peoples AI and repurpose it or you could even use some API for image/audio recognition like Amazon's Transcribe Speech-to-Text API, PocketSphinx, Mozilla's DeepSpeech, Google Speech or Wit.AI.
But there are also people who already wrote a Library to implement those tools - One of them is GoodByeCaptcha by MacKey-255.
It uses FFmpeg (great tool by the way), Microsoft Azure, Amazons Transcribe, YolvoV3, Wit.AI or Pocketsphinx to recognize speech/images and solves the captcha for you - I am not going to show you how to implement it into your python code, the author made a good text tutorial here or a good video tutorial here.
9. Hold cookies
It might be worth collecting and holding on to cookies in certain cases.
Most people scraping do not keep their cookies by using an incognito window and or restarting and not keeping your cookies. But this can become suspicious to some websites.
Like I already said above, websites could set a cookie on one site and check if it exists on another. This way they can track your Page flow for example.
Provided you do not mind getting customized results, it might be a good idea not to always use incognito/restart incognito every time you make a new request so that you keep your cookies
There are 2 good methods for keeping cookies, i would recommend the Second Method for most use cases, but maybe you want to play around a bit, so I'm still going to give you the first method ^^
1. Save the current cookies as a Python object using pickle:
import pickle
from selenium import webdriver
driver = webdriver.Chrome(chrome_options=chrome_options)
driver.get("https://www.google.com")
pickle.dump(driver.get_cookies(), open("cookies.pkl","wb"))
And later to add them back:
import pickle
import selenium.webdriver
driver = webdriver.Chrome(chrome_options=chrome_options)
driver.get("http://www.google.com")
if os.path.isfile("cookies.pkl"):
cookies = pickle.load(open("cookies.pkl", "rb"))
for cookie in cookies:
driver.add_cookie(cookie)
2. Chrome options user-data-dir in order to use folders as profiles:
Add this code to your Bot and all cookies will be present from now on (Minus the cookies, which normally expire due to time or because they are only to be kept during the session, of course.):
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument("user-data-dir=selenium")
driver = webdriver.Chrome(chrome_options=chrome_options)
driver.get("https://www.google.com")
The advantage is that you can use multiple folders with different settings and cookies, Extensions without the need to load, unload cookies, install and uninstall Extensions, change settings, change logins via code, and thus have no way to break program logic, etc.
10. Backing Off
What several crawlers and scrapers struggle to do is back-off as 403/503 errors begin to be served. By simply ignoring those messages and asking for more sites after you get these errors, it becomes fairly obvious that you are really a bot and not a person - No human will try to reload a page 1000 times after they get an error to stop trying.
Just slowing down and backing down when you get errors will help you avoid damaging your IP reputation and banning yourself.
Just perform a small check for these errors and stop the program/sleep some time before you try again.
11. Ultrafunkamsterdam’s ChromeDriver
Ultrafunkamsterdam created a ChromeDriver that already includes Points 1 and 2 of this article, as well as many other features. (I had planned to make a ChromeDriver similar to this, but he was first^^)
Because this project is open source, it should be updated fairly frequently, allowing the chromedriver to remain undetected.
It can currently mitigate all major bot detection systems such as Distil, Datadome, Cloudflare, and others. This may change in the future as those providers update their systems, especially since they have access to this chromedriver and may be able to find something identifying it somewhere.
But for the time being, it's a fantastic tool; all you have to do is:
pip install undetected-chromedriver
Then, just as you would with regular selenium, work with it:
import undetected_chromedriver.v2 as uc
options = uc.ChromeOptions()
# setting profile
options.user_data_dir = "c:\\temp\\profile"
# another way to set profile is the below (which takes precedence if both variants are used
options.add_argument('--user-data-dir=c:\\temp\\profile2')
# just some options passing in to skip annoying popups
options.add_argument('--no-first-run --no-service-autorun --password-store=basic')
driver = uc.Chrome(options=options)
with driver:
driver.get('https://nowsecure.nl') # known url using cloudflare's "under attack mode"
This chromedriver isn't a magic bullet for hiding all your bots!
You'll still need to follow the other tips in this article, such as realistic page flow, changing your IP, not using a headless browser, keeping cookies, backing off, and so on.
However, if you are using Python, this is a great place to start in order to keep your bot undetected, at least on the technical chromedriver site.
12. User data consistency
I already mentioned consistency in point 3 in terms of your OS, Browser, and so on matching up with your User Agent and all.
However, another critical point where consistency is required is when logging in with user Accounts.
When reviewing other people's bots, I encountered this issue quite frequently. They frequently randomize their User Agent, IP, and whatever else I mentioned previously, but then forget that this makes no sense when logging in with a user account.
For example, suppose you have User A, who has an IP address from Germany on the first login, but when you log in with this account the next time, you randomize the IP/Proxy and he now has a Russian IP address.
This would imply that the user simply traveled to another country while not logged in. This is sometimes plausible, but if you then change his IP address to, say, Argentina, your user would have to be a quite frequent traveller for this to be realistic lol.
The same is true for the User Agent; you can't simply change the browser and operating system he's using every 5 minutes. Especially if he has a Chrome version 91 once and then a version 89 Browser 5 minutes later, then a version 90, then a 91 again, and so on...
This would imply that he constantly downgrades and upgrades his browser.
This is simply not realistic behavior.
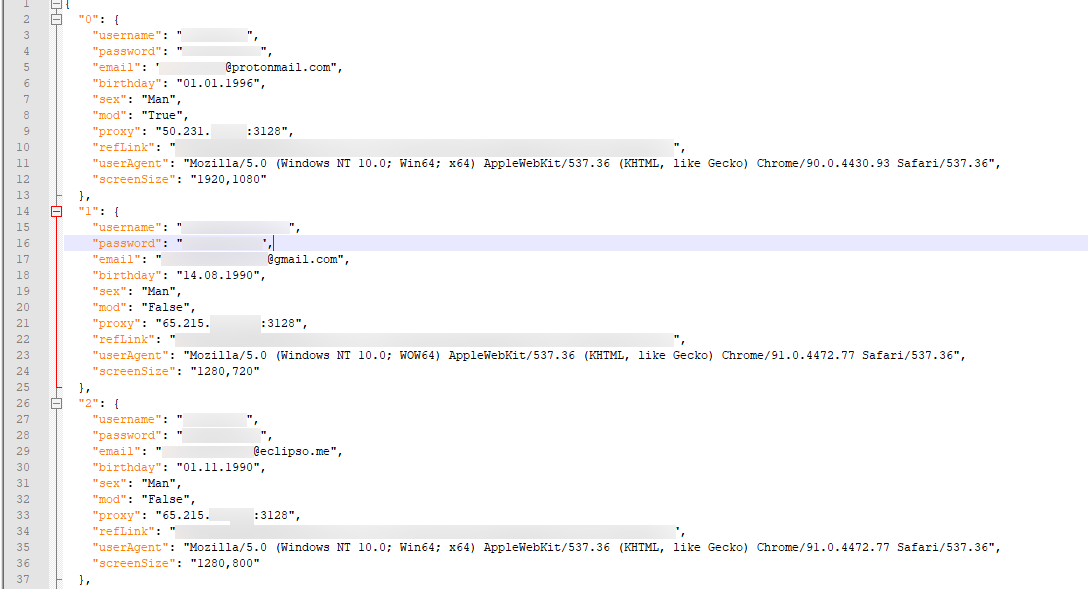
So, in a nutshell, if you still don't understand what I mean: Maintain a text file (or json, a database, or whatever) containing the user's name, password, user agent, IP address, etc. Then, whenever you log in with this user, you should always use this data.
Above is a screenshot of an example Json File, with some details blurred out.
Conclusion
When it comes to preventing Bot detection, there's no magic bullet. Every technique has its advantages and disadvantages.
And as time passes, some of the strategies I've spoken about are likely to be taken into account by website owners, and then new techniques to conceal them will be discovered. It's a never-ending game of cat and mouse.
But for now, these are probably the best ways to conceal your (Selenium) Bot from detection.
Further Resources
Besides some great books that you can see below, 33C3 (This one is mainly German material, but if you're a German, using subtitles or the like, these talks are very cool.), DEF CON and Black Hat are fantastic resources to learn about things like this. Just search “33C3 Talk”, “DEF CON Talk” or “Black Hat Talk” on YouTube and you'll find loads of recorded talks.


Mining the Social Web: Data Mining Facebook, Twitter, LinkedIn, Instagram, GitHub, and More

Web Scraping with Python: Collecting More Data from the Modern Web
Keep in mind that as an Amazon partner, I earn from qualified sales