
Web Crawler
Crawling would be essentially what Google, Yahoo, MSN, etc. are doing, looking for ANY information linking websites together.
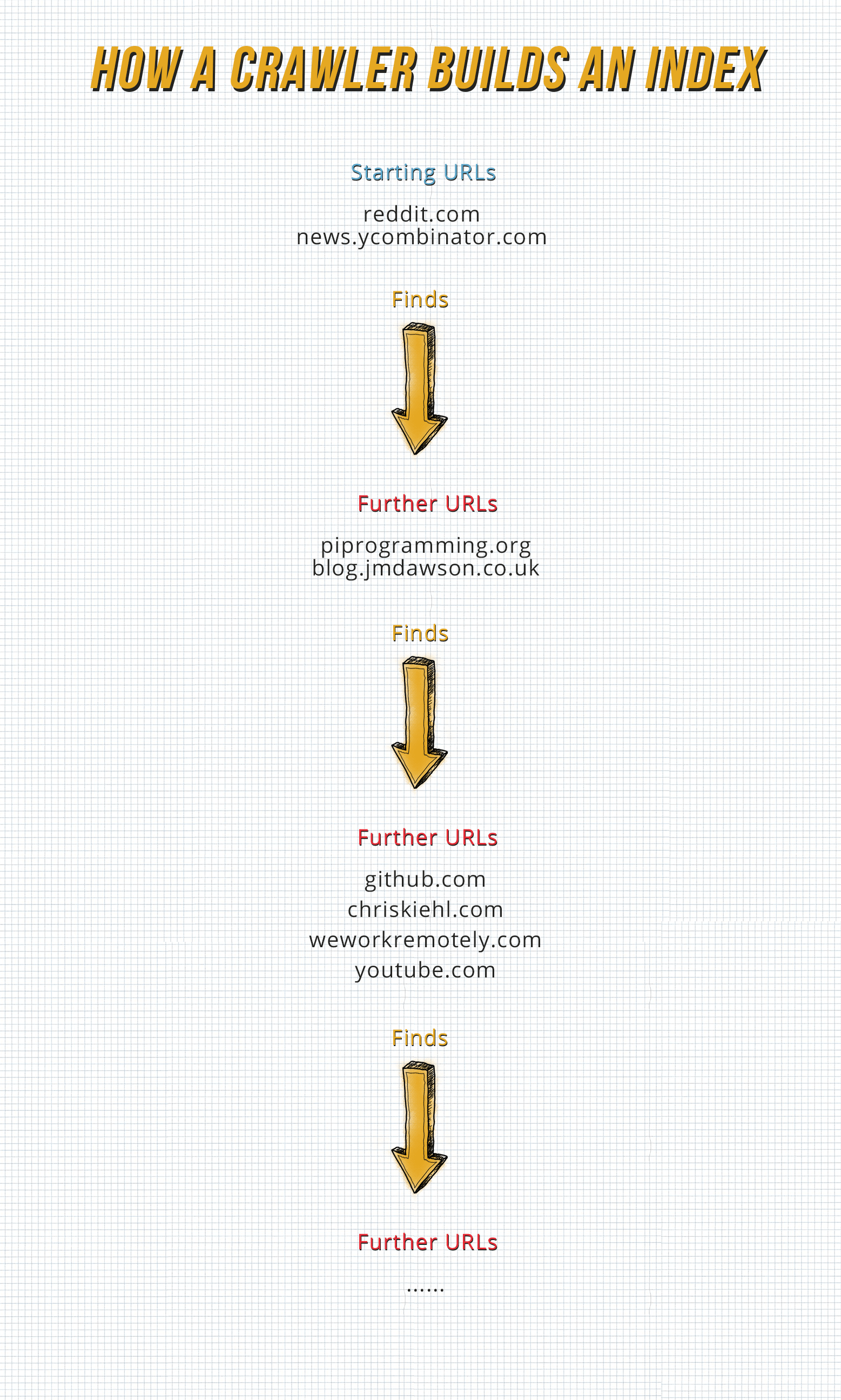
Web crawling is just a process of iteratively going around and visiting websites to find and retrieve web links from a list of starting Websites to build a database (index) of the layout of that site and the sites to which it links to.
But crawlers don't just pick up every link on a website. There are so-called "no-follow" links that the web crawler just ignores, and as the name might already tell you, the crawler doesn't follow them to the website it links to.
Strictly speaking, to do web crawling, you also need to do some kind of web scraping to extract the URLs so this kinda blurs the line between crawling and scraping.
Web Scraper
Web Scraping means extracting data from websites (and is mostly targeted at only certain websites and not just any websites that exist), for specific data, e.g. for a price comparison tool.
Scraping can mean getting data by hand by copying and pasting it, but it usually involves a custom-made program that use text pattern matching or HTML pattern matching for a certain website it is supposed to be scraping or, nowadays there are even general purpose Web Scraping tools that use Computer Vision or other Artificial Intelligence to extract data, and would be doing things a good crawler wouldn't do, i.e.:
- Ignore the robots.txt
- Disguise itself as a normal User
- Submit forms with data
Comparison Table
| Web Crawler | Web Scraper |
| Only extracts URLs on Website. | Extracts Data from Website. |
| Openly disclose that they are not a real user. | Hide themselves from Website. |
| Do not submit forms so as not to disturb the Website Owner. | Do submit forms if it is necessary to get some data without regarding the damage it could cause. |
| Respect the robots.txt so as not to go on Sites where Bots should not be. | Ignore the robots.txt if it is necessary to get some data. |