
During recent years, we have seen more and more artificial intelligence apps transition to mobile devices such as smartphones, smartwatches, etc. and ever-increasing neural networks with more nodes and layers being considered (GPT-3 is a recent example of this).
This raises the major problem of implementing AI models on portable devices with limited resources - a large number of weights in models typically makes it impossible for models to be deployed in low storage and memory environments.
That's why I have put together the following techniques for you - not only to achieve higher model compression but also to reduce the computing resources required (e.g. CPU, Memory, Battery Power, Bandwidth). This will help your model deployment on cell phones, IoT devices, and so on.
How compression of AI Models works:
Convolutional Filters / Quantization
Quantization is the process of representing connections with fewer bits by grouping or rounding weights, which reduces memory usage and the processing power required.
Weights are stored in Deconvolutional Neural Networks as 32-bit floating-point numbers - this is why the weights can be quantized to 16-bit, 8-bit, 4-bit, and sometimes 1-bit. This can significantly reduce the size of the deep neural network.
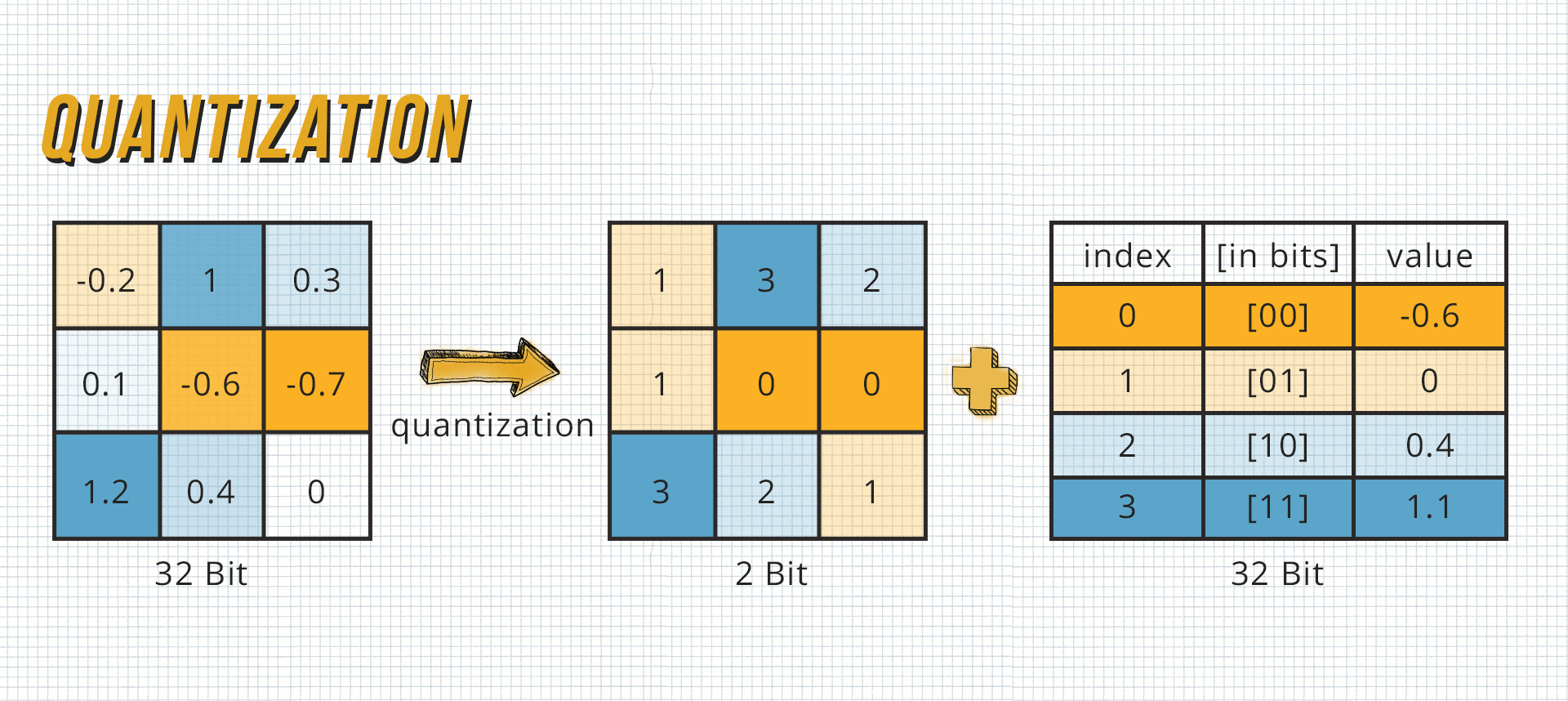
Again, as with pruning, after quantization, you need to fine-tune the model. It should be noted here that the properties that were given to the weights during quantization should also be retained during fine-tuning.
Quantization has the advantage of being able to be used during and after training. The disadvantage, however, is that the convergence of neural networks is more difficult and therefore a lower learning rate is needed.
Parameter Pruning And Sharing
Pruning is a compression process involving the selective removal of some uncritical and redundant connections present in the model which are not sensitive to the performance, such as unimportant weights, typically defined as small absolute weights.
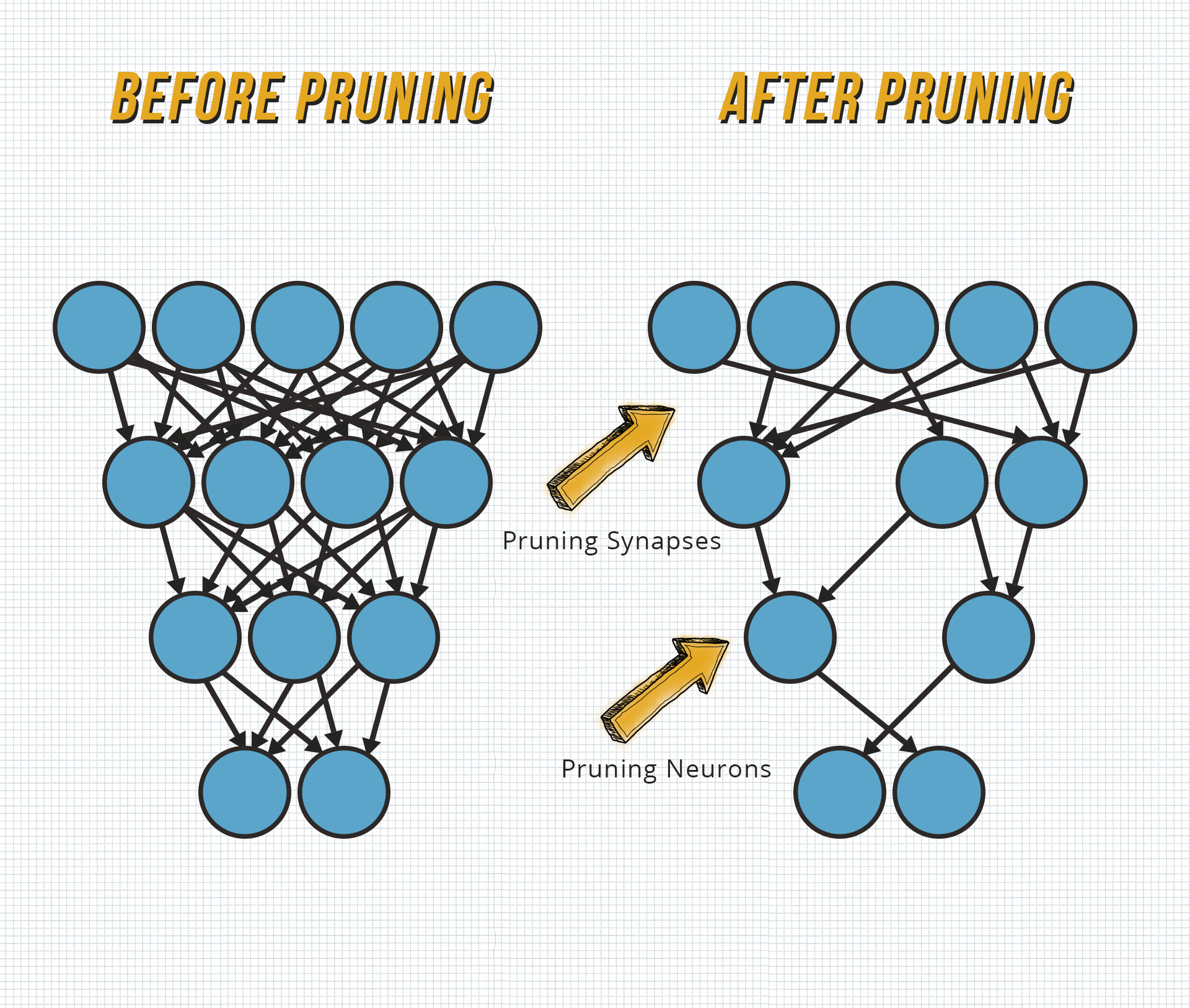
The new model will then have lower accuracy, but this can be overcome by fine-tuning - CNNs and fully linked layers can typically have up to 90% sparsity without losing any precision.
Low-Rank Factorisation
Low-Rank Factorisation uses matrix/tensor decomposition to estimate the informative parameters - This basically divides a large matrix into smaller matrices.

Low-Rank Factorisation has the advantage of being able to be used during and after training, and when used during training, the training time can even be reduced.
Selective Attention
Selective attention is the mechanism, similar to that of the human eye, of focusing on some elements and ignoring other irrelevant elements. Since, for example, the human eye only sees those irrelevant things in a blurred way when you focus on something.

Selective Attention even increases accuracy by focusing the AI only on the regions of interest but the disadvantage, however, is that it can only be used when you are training your model from the ground up.
Knowledge Distillation
In knowledge distillation, a large, complex model (teacher model) is trained on a large dataset and when this large model can generalize and perform well on unseen data, you train a more compact model (student model) to reproduce the output of the larger one.
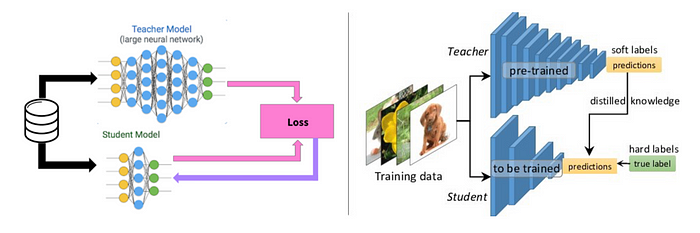
Knowledge Distillation has the advantage that if you have a pre-trained teacher model, less training data is needed to train a smaller student model and that if you have a pre-trained teacher model, the training time of your final model (the student model) can even be reduced.
The downside, however, is that if you don't have a pre-trained teacher network, you may need a larger dataset and more time to train your final model (the student model).
7 Ways to compress your Deep Learning, Neural Network, etc. AI Model
Now let's take a look at a couple of papers that have introduced compression models.
1. 3LC: Lightweight and Effective Traffic Compression
3LC is a loss compression scheme developed by Google that can be used for state-of-the-art traffic in distributed machine learning that strikes a balance between traffic reduction, precision, generality, and computing overhead.
It integrates value quantization with base encoding, zero-run encoding, and multiplication of sparsity and achieves a data compression ratio of up to 107X, nearly the same test accuracy of trained models and high compression speed.
2. Efficient Neural Network Compression
This paper proposes an effective way to get the entire network configuration ranked. While the previous methods looked at each layer separately, this method takes into account the entire network in order to get the correct configuration.
3. MLPrune: Multi-Layer Pruning For Neural Network Compression
It is computationally costly to manually set the compression ratio of every layer in order to determine the perfect balance between the size and precision of a model.
This is why this paper addresses the Multi-Layer Pruning Process, which can automatically evaluate the correct compression ratios for all layers.
4. Universal Deep Neural Network Compression
This research implements universal Deconvolutional Neural Network loss compression through weight quantization and lossless source coding for memory-efficient deployment for the first time, while previous work only dealt with non-universal scalar quantization and entropy coding for Deconvolutional Neural Network weights.
This discusses the universal randomized lattice quantization of Deconvolutional Neural Networks, which randomizes weights by uniform random dithering prior to lattice quantization and can operate almost optimally on any source without relying on knowledge of its probability distribution in particular.
5. Weightless: Lossy Weight Encoding
This paper introduces a novel scheme for weight loss encoding that complements traditional compression techniques. This encoding is based on the Bloomier filter, a space-saving probabilistic data structure that can cause errors.
By using the ability of neural networks to handle these imperfections and by retraining errors, the proposed technique, Weightless, will compress Deconvolutional Neural Network weights by up to 496x with the same model accuracy.
6. Compression using Transform Coding and Clustering
This work provides another view on the compression of deep models without fine-tuning. It has been well validated not only on large deep models such as VGG and AlexNet but also on lightweight deep models such as SqueezeNet.
It proposes an efficient neural network compression approach with DCT transformation and quantization by considering the scale factor to achieve a high compression ratio while sustaining good performance. In addition, the compression method consists of transforming and clustering with high encoding efficiency. This can also be paired with current deep model compression approaches.
7. Adaptive Estimators Show Information Compression
This paper proposes more reliable mutual information estimation techniques that conform to the hidden behavior of neural networks and deliver more accurate activation measurements of all functions. Such adaptive estimation techniques have been used to investigate compression in networks with a variety of different activation functions.
The most important finding is that the activation functions are clearly not about gradient flow and that they can have properties that are more or less attractive depending on the domain they might be used on.
Conclusion
In this article, I looked at the different ways to compress your AI Model so that you can use it on a device with limited resources, such as an IoT device, without losing too much accuracy.
All of the above techniques are complementary - they can be applied as-is or paired with each other. For example, a three-stage pipeline, pruning, quantization, and Huffman coding could be used to reduce the size of an already trained model.
It's also nice to see that many machine learning frameworks have Quantization baked into them now, so you have less work to do.